
模仿黑产破解12306验证码,验证码产品的未来是?
验证码,人类与机器不平等的对抗
在AI的新时代背景下,破解一款验证码的成本正变的越来越低。
很多时候,看似复杂的谷歌街景、12306验证码、让人望而却步的百万图库,实际并不复杂:
-
12306验证码有多少种问题呢?——其实只有100种。
-
他的数百万图库需要多少样本可以训练识别?——只需要5万张。
-
需要花费多少标记成本呢?——只需要500块。
-
破解花费了多少时间?——作者一周的零碎时间。
-
模型需要多少计算力?——GTX1070上训练20分钟。
-
识别速度呢?——接口虽然慢其实只是部署在2核2G的云机器上而已。
言而总之,现在的人机识别的对抗已经不再是人力对抗人力,图像的识别也已经不再像传统验证码识别一样,需要人工去耐心地分析每一种特征然后做切割和字库。如今端到端的CNN模型完美的解决了纯图像分类问题。字符型验证码,也不再需要二值预处理分割等复杂操作,一个4层的仿alexnet的网络模型就可以轻松达到90+的准确率。
目前的验证码行业,业界多数还围绕在谁更难看,更复杂的发展方向上。有的渐渐步入“反人类深渊”,比如苹果app商店的。
也有的取自自然场景防止爆破,比如谷歌的街景路牌:

然而,黑产的破解方案只考虑结果,经过作者的简单统计,谷歌验证码出现街景问题的概率高达40%,出现汽车或者道路的概率为30%。坏人只需要做出一个路牌定位器,然后通过无限刷新验证码,就可以只验证路牌类的问题,从而无视其余复杂的自然场景。那么,研发一个路牌定位器需要多少资源?笔者采用fast-rcnn算法,仅需要500张粗糙标注的样本,30分钟训练便有了上图的定位效果。
12306验证码是如何破解的呢?
回到12306验证码,要解决这款验证码,本质上是一个 分类问题。

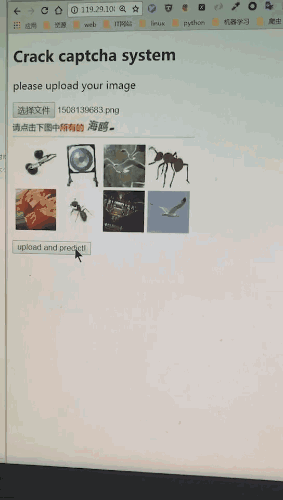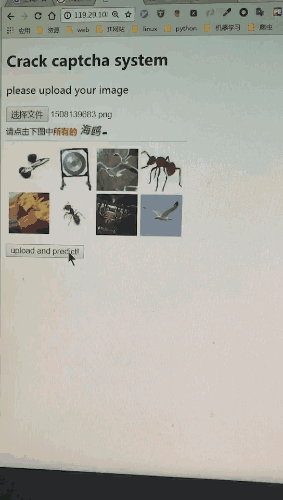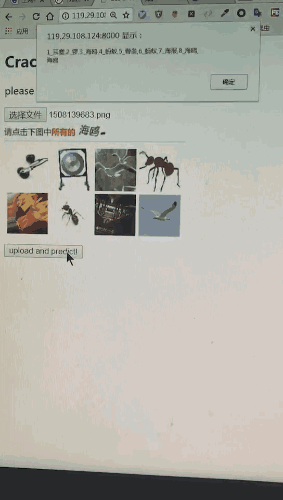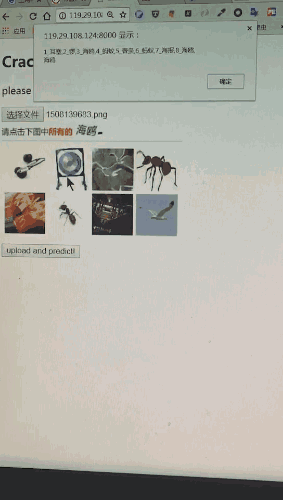
文本的分类:
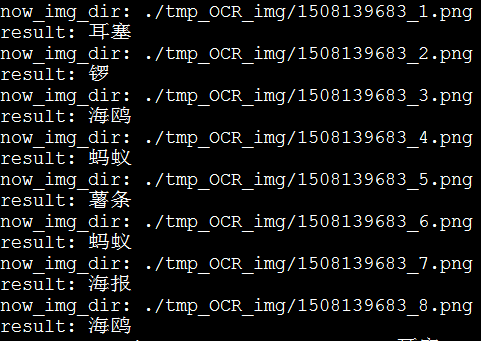
将下图中的问题部分200*30的区域截取处理,利用某开放的OCR接口去识别,会有80%的识别准确率。这个成功率并不乐观,因此我们自己做了一个问题识别器。假如将全部OCR结果直接投入Alex-net中,会存在大量的错误数据,得到的分类器成功率将低于10%,效果很差。但是依据概率清洗,统计完OCR识别结果的图片,把出现频率高的认为是一个标签,就会发现在5万张图片中,平均每个问题的出现率为1%。去除出现频率特别低的样本数据后(比如口哨偶尔会识别成口肖,出现频率低则去除该样本),重新训练识别成功率则高达99%,扭曲的问题文本形同虚设。

12306验证码基础版本会出现的问题如下:
['日历', '薯条', '口哨', '蜥蜴', '蒸笼', '护腕', '印章', '蜜蜂', '文具盒', '绿豆', '菠萝', '铃铛', '剪纸', '耳塞', '手掌印', '锣', '仪表盘', '红枣', '金字塔', '电线', '老虎', '', '辣椒酱', '挂钟', '双面胶', '啤酒', '蜡烛', '雨靴', '毛线', '茶几', '茶盅', '档案袋', '盘子', '狮子', '订书机', '篮球', '国结', '开瓶器', '打字机', '热水袋', '海鸥', '电子秤', '排风机', '风铃', '棉棒', '鞭炮', '龙舟', '电饭煲', '锅铲', '珊瑚', '蚂蚁', '红豆', '海苔', '钟表', '卷尺', '冰箱', '苍蝇拍', '烛台', '药片', '调色板', '创可贴', '沙包', '话梅', '本子', '安全帽', '海报', '刺绣', '牌坊', '网球拍', '路灯', '航母', '高压锅', '黑板', '拖把', '锦旗', '公交卡', '红酒', '跑步机', '樱桃', '沙拉', '漏斗']
图像的分类:
方法仍然是把标记好的图片投入VGG-16层的模型中,初期得到的识别结果较差,因为标记数据并不会完全正确,事实上现在的通用模型已经十分完善,训练的结果非常依赖数据清洗的效果。
然而,有没有得到高精度区分标记正确与否的样本集的办法呢?答案在于网站。
绝大多数网站, 都会在登录页面存在验证码,而用户常识登录时,会首先校验验证码是否正确,其次是账号密码,因此就是自己生产一堆随机账号密码,去撞登录网页,发现验证码校验通过了,但是账号密码错误,就可以有效筛选出正确的标记数据。
同样的思路,如果我用现在已经达到95%的识别模型去重复这个样本标记的行为,将得到的就会是远比现在5W样本集多的多的样本量,可预期将得到的准确率会更高,当然会有同学说,那样你的模型将局限在这类问题下,而不能成功适应他新的图像,一旦更新不就失效了吗?
是的,但是解决实际问题的时候,一些小tips就能解决这样问题,
问:如何应对验证码图片的更新迭代?
答:只识别模型能识别的验证码,在高并发刷新下即使只能识别5%的问题,实际应用也是100%。
问:如何让模型自己学习没遇到过的图像?
答:将非模型可识别的问题和图片标记为 _ 交付人工打码,将打码结果重新训练模型。
问:上面的问题有没有高级点的解决办法?
答:撞验证码库,新出现的问题随机性标注,8个格子随机撞约有2%的成功率,学会一个新物体也只需要500张样本,撞10W次即可。
问:能不能别这么流氓?
答:不能,因为面对实际问题与巨大利润,坏人就是这么流氓。
验证码场景的对抗该何去何从?
在验证码这类场景的人机对抗是十分不平等的,坏人哪怕在识别上做到5%的识别,也能通过撞的手法当成100%,固定类型的验证码图像又能够被低价打码获取到样本,即使是谷歌那样自然背景缺乏更新迭代也难逃黑手,持续的在图像方面纠缠就会走向12306和苹果那样影响用户体验的产品。
面对恶意的抗争,同样要掌握对手的思维,或许实验室中图像识别率达不到90%以上就是失败的模型,但是放在黑产中5%就是一个能赚钱的模型。
或许并不该用破解率去作为唯一指标,面对新时代的黑产,更应该用黑产的角度来反思现在的方向,从对抗的角度除了识别率,更多去牵制黑产需要动用的资源成本,破解率,识别速度,打码成本,训练成本,更新迭代的速度,后台策略更新的速度,来综合衡量一个验证码产品。
体系化以成本为评估的验证系统
例如谷歌的验证码,时不时会弹出4*4个格子的汽车道路识别,意味着坏人要做16次的CNN分类,然而在校验的过程中,他会充满互动,识别出若干后还会随机弹出若干要求继续识别,这样即使最终能被破解,坏人所需要的计算力成本时间交互成本就远远大于普通验证码。并且后台还有更多浏览器行为,设备指纹,IP等普通用户看不到的属性在综合形成人机识别的体系。
就像我们的VTT验证码新物体新逻辑问题快速迭代半小时快速上线,而即使坏人要采用fastrcnn等算法进行目标定位破解,则需要数十倍的标注成本以及多倍人力不断跟随迭代,而不再是传统字符验证码几分几厘的标注成本,自动化破解无需人力调参。而坏人在破解过程中用到的ip资源设备指纹等,又有其他策略进行对抗,因此验证码将不再只是一张验证码图片而是一套人机验证系统,一套的围绕着影响坏人成本的人机识别体系。
在这种体系下我们看到的验证码将会是最可爱可亲的情切的图片,一键的点击,通过无数只有真人具备的特征才能通过这道验证。
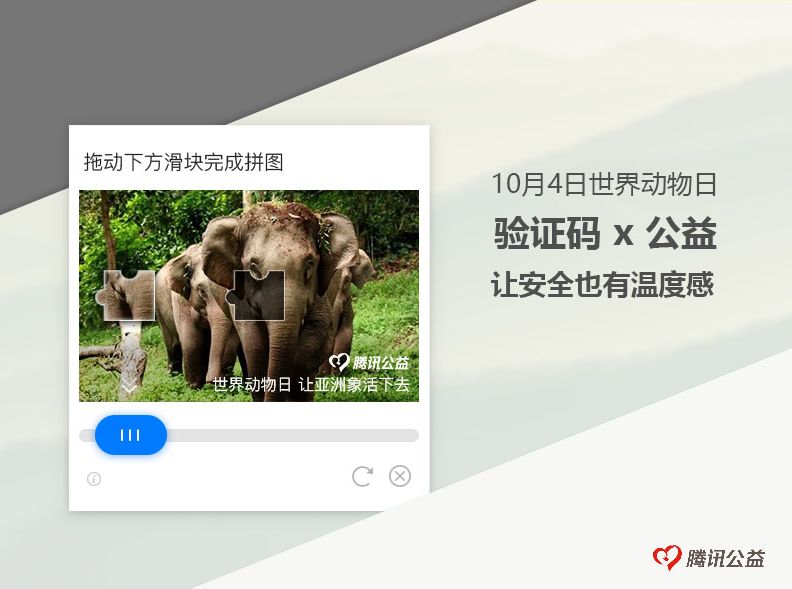
也会看到利用机器学习在理解人类逻辑的薄弱点而推出的
基于逻辑语义的VTT(Visual Turing Test)验证码
VTT验证码需要用户根据题目,选出图中一个或者多个答案物体,通过点击、拖动、连接等方式选中区域提交给后台判断。在保证体验依旧简单无需输入的基础上,实现了良好的对抗效果。VTT的图片由后台3D渲染随机产生,保证图片不会重复,语义也可以根据题目中的图片中的物件属性组合产生,多种多样的变化可以有效阻挡恶意。


或许要不了多久,坏人依旧诱惑于高额利润最终突破我们的验证码,而我们也将不断从红蓝对抗中,越战越强。