
Python爬取APP数据,进行APP逆向分析!
某漫画app逆向
- 一工具的准备
- 二项目思路
- 三简易代码提供参考
一工具的准备
- 1.fiddler抓包工具 ,夜神模拟器
- 2.python环境,Java环境
- 3.漫画app准备
- 4.java反编译工具
二项目思路
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:701698587
配置好抓包工具和夜神模拟器
豆瓣夹下载漫画applink.
安装到夜神模拟器
抓取app数据
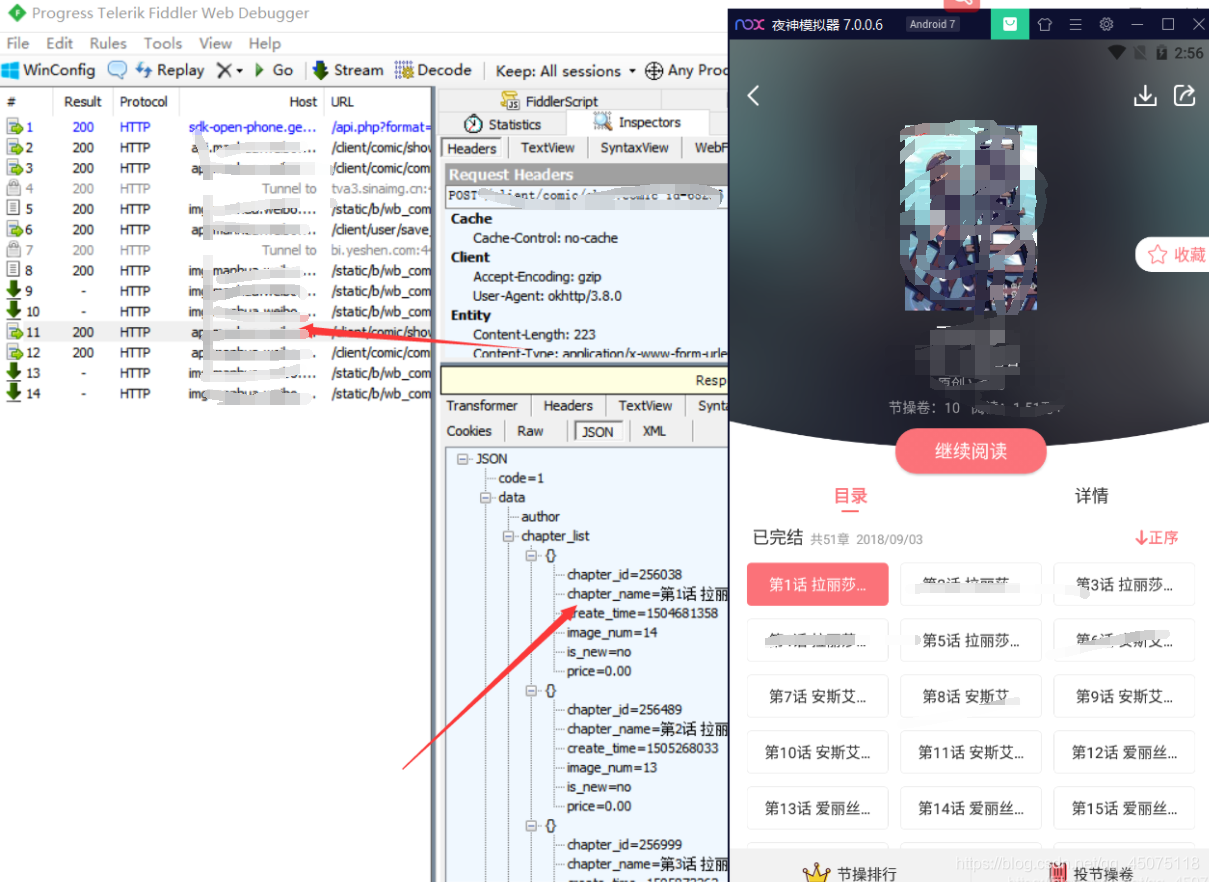
解析抓取的数据:
post请求
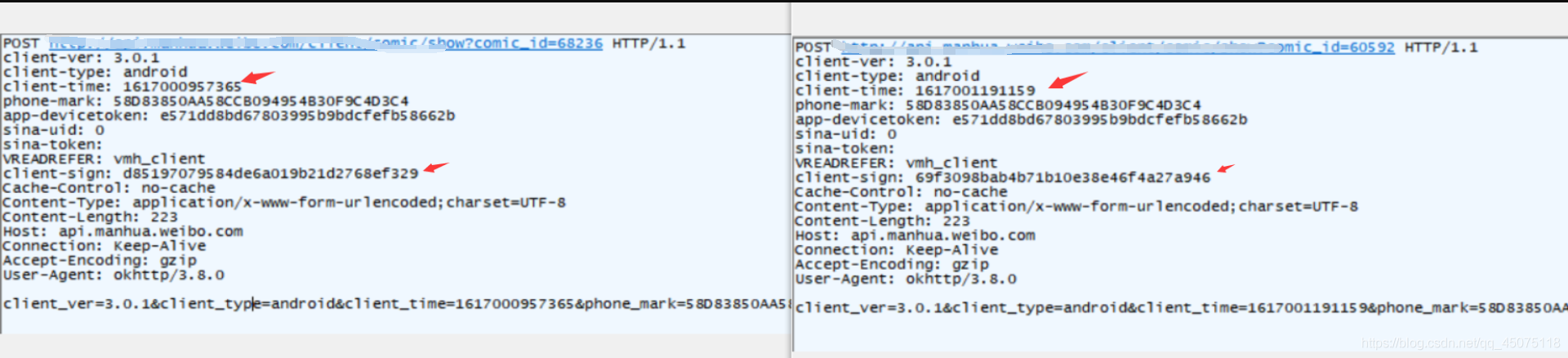
变化的参数client-time, client-sign
client-time 比较明显是时间戳
client-sign 是加密数据
client_type = 'android'
app_devicetoken = "e571dd8bd67803995b9bdcfefb58662b"
phone_mark = "58D83850AA58CCB094954B30F9C4D3C4"
client_time = str(int(time.time() * 1000))
解析app
将apk安装包后缀修改为rar, 解压压缩包得到app对应文件

得到Java的classes文件
对获取的classes.dex进行反编译,工具可以自行查找,或者沟通群获取
将classes.dex 移动到解析的文件夹
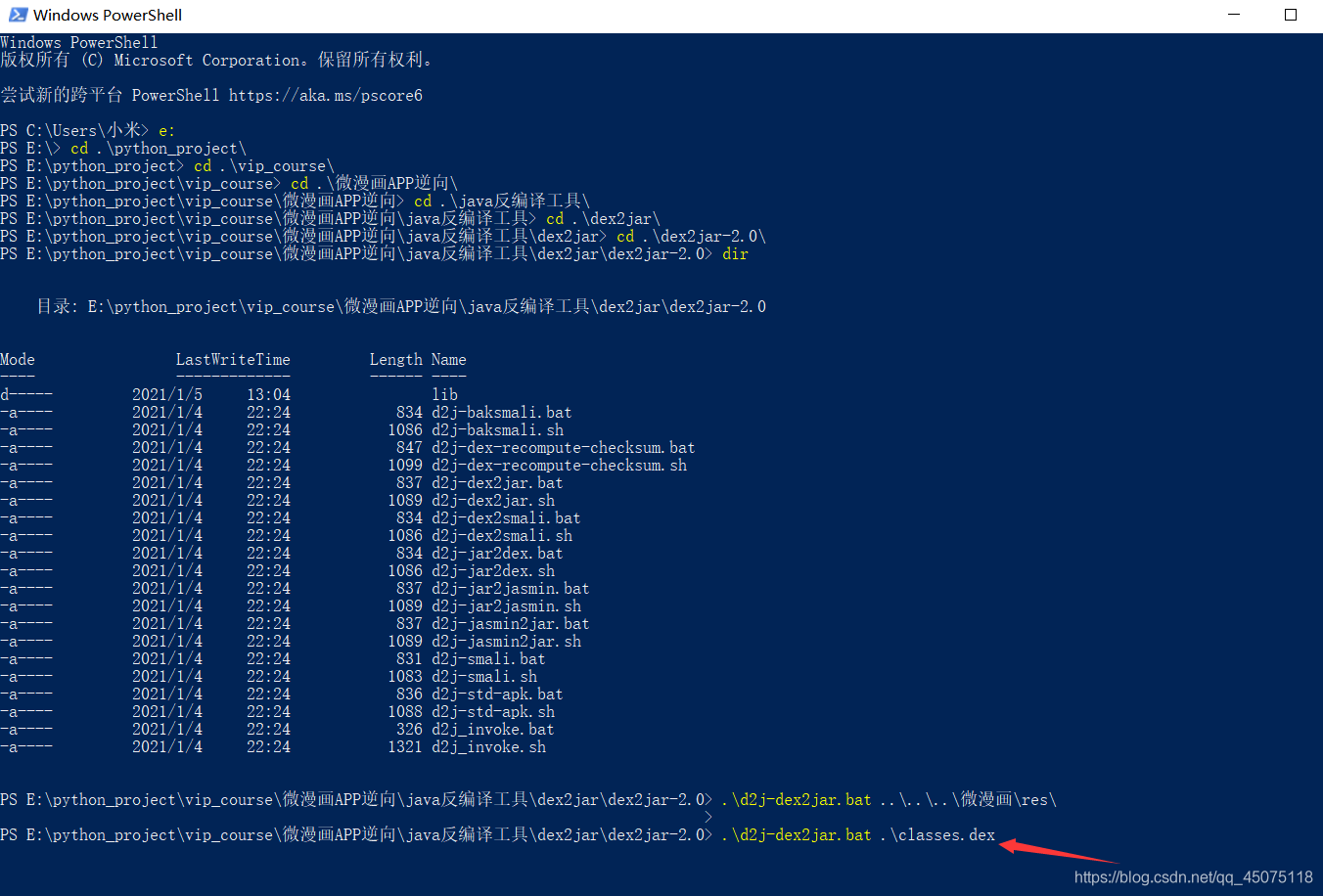
进入windows powershell cd 到反编译的文件夹
执行命令 .\d2j-dex2jar.bat .\classes.dex
得到 classes-dex2jar.jar 文件 这个就是java的源代码了

将代码拖动到你的java反编译器 JD-GUI

就能得到全部的java代码
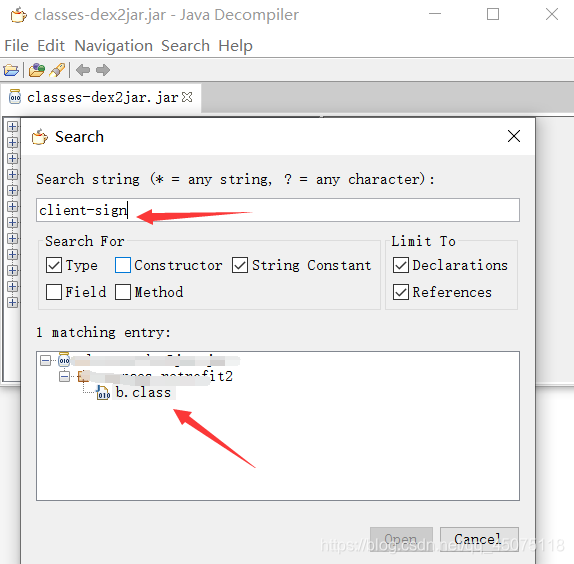
搜索对应的加密参数:client-sign
确定生成client-sign 为b.class 打开对应文件
找到数据的加密规则
原来加密的方式是md5
加密的数据是由时间戳来决定的
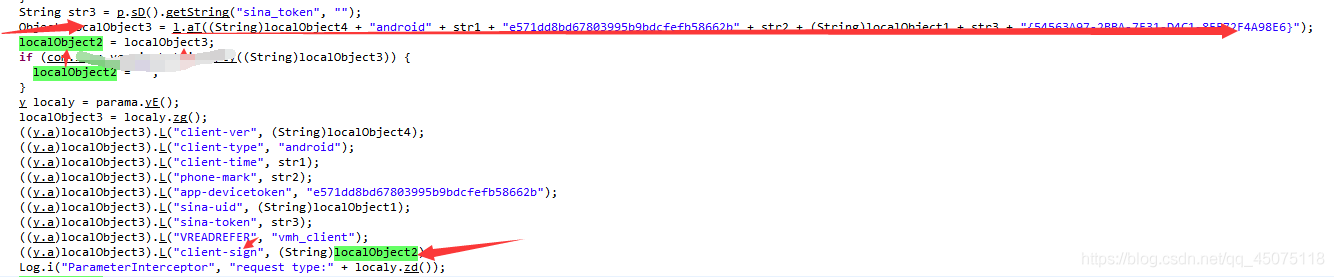
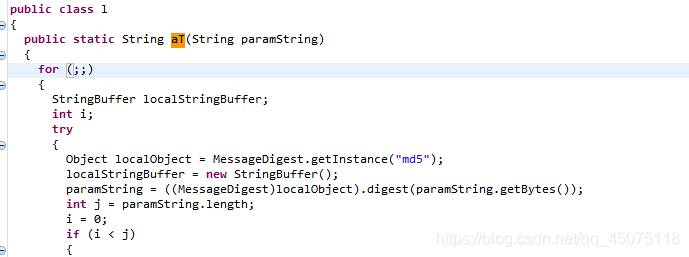
content = '3.0.1' + client_type + str(client_time) + app_devicetoken + phone_mark + "0" + "" + "{54563A97-2BBA-7F31-D4C1-8EF72F4A98E6}"
client_sign = hashlib.md5(content.encode("utf-8")).hexdigest()
1
2
确定请求头的全部参数
headers = {
'client-ver': '3.0.1',
'client-type': client_type,
'client-time': str(client_time),
'phone-mark': phone_mark,
'app-devicetoken': app_devicetoken,
'sina-uid': '0',
'sina-token': '',
'VREADREFER': 'vmh_client',
'client-sign': client_sign,
'Cache-Control': 'no-cache',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Content-Length': '223',
'Host': 'api.manhua.weibo.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0',
}
需要传递的参数
data = "client_ver=3.0.1&client_type={}&client_time={}&phone_mark={}&app_devicetoken={}&sina_uid=0&sina_token=&client_sign={}".format(client_type, client_time, phone_mark, app_devicetoken, client_sign)
三简易代码提供参考
内容涉及该app, 只限技术探讨
import requests
import time
import hashlib
import os
client_type = 'android'
app_devicetoken = "e571dd8bd67803995b9bdcfefb58662b"
phone_mark = "58D83850AA58CCB094954B30F9C4D3C4"
client_time = str(int(time.time() * 1000))
content = '3.0.1' + client_type + str(client_time) + app_devicetoken + phone_mark + "0" + "" + "{54563A97-2BBA-7F31-D4C1-8EF72F4A98E6}"
client_sign = hashlib.md5(content.encode("utf-8")).hexdigest()
headers = {
'client-ver': '3.0.1',
'client-type': client_type,
'client-time': str(client_time),
'phone-mark': phone_mark,
'app-devicetoken': app_devicetoken,
'sina-uid': '0',
'sina-token': '',
'VREADREFER': 'vmh_client',
'client-sign': client_sign,
'Cache-Control': 'no-cache',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Content-Length': '223',
'Host': 'api.manhua.weibo.com',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.0',
}
data = "client_ver=3.0.1&client_type={}&client_time={}&phone_mark={}&app_devicetoken={}&sina_uid=0&sina_token=&client_sign={}".format(client_type, client_time, phone_mark, app_devicetoken, client_sign)
def parse_data(url):
response = requests.post(url, headers=headers, data=data).json()
page_list = response["data"]["chapter_list"]
for x in page_list:
page_url = "http://api.manhua.weibo.com/client/comic/show?comic_id=68236/client/comic/play?chapter_id={}".format(x["chapter_id"])
dir_name = r"漫画\\" + x["chapter_name"]
page_data = requests.post(page_url, headers=headers, data=data).json()["data"]["json_content"]["page"]
y = 0
for i in page_data:
if not os.path.exists(dir_name):
os.makedirs(dir_name)
result = requests.get(i["mobileImgUrl"]).content
path = dir_name + "\\" + str(y) + ".jpg"
with open(path, "wb")as f:
f.write(result)
print("正在下载", path)
y += 1
def main():
url = "http://api.manhua.weibo.com/client/comic/show?comic_id=68236"
parse_data(url)
if __name__ == '__main__':
main()